About
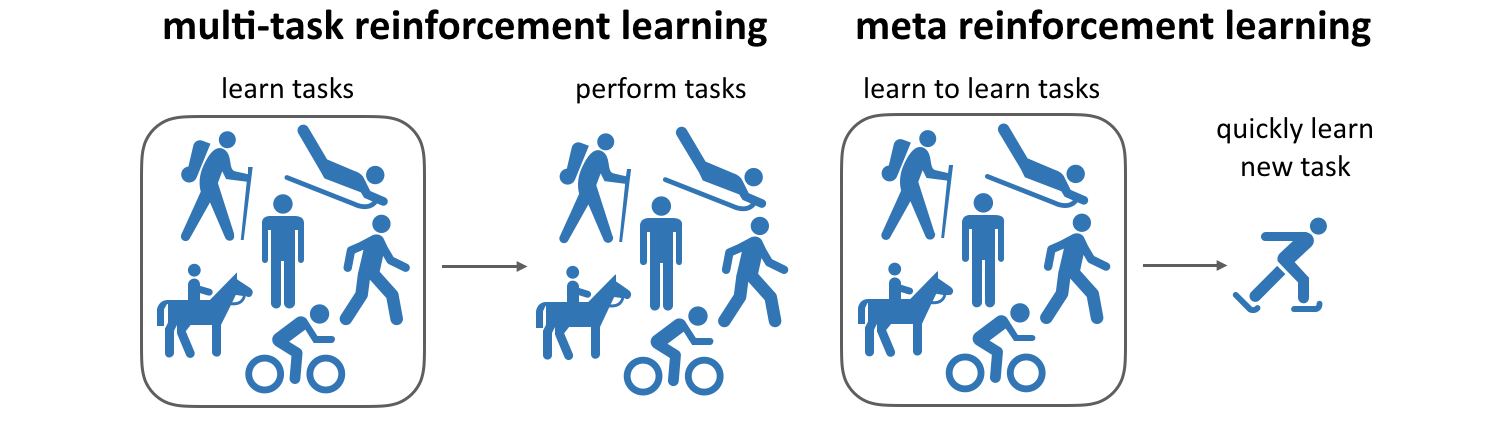
In multi-task learning and meta-learning, the goal is not just to learn one skill, but to learn a number of skills. In multi-task RL, we assume that we want to learn a fixed set of skills with minimal data, while in meta-RL, we want to use experience from a set of skills such that we can learn to solve new skills quickly.
To evaluate state of the art multi-task and meta-learning algorithms, we need a diverse yet structured set of skills to evaluate them on. The Meta-World benchmark contains 50 manipulation tasks, designed to be diverse yet carry shared structure that can be leveraged for efficient multi-task RL and transfer to new tasks via meta-RL. The Meta-World benchmark has three different difficulty modes for evaluation, described next.
Meta-Learning 1 (ML1)
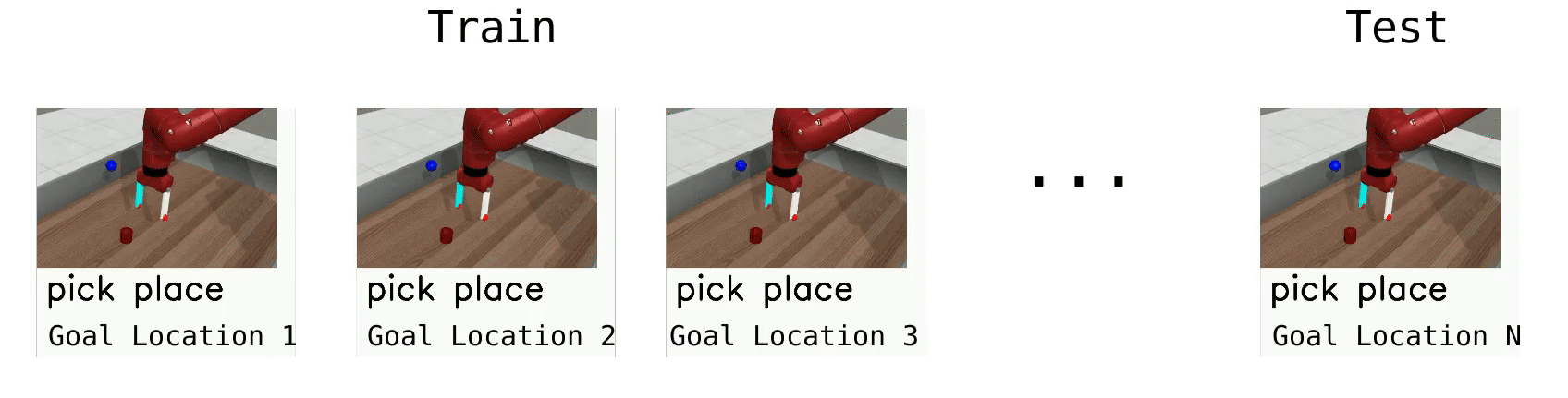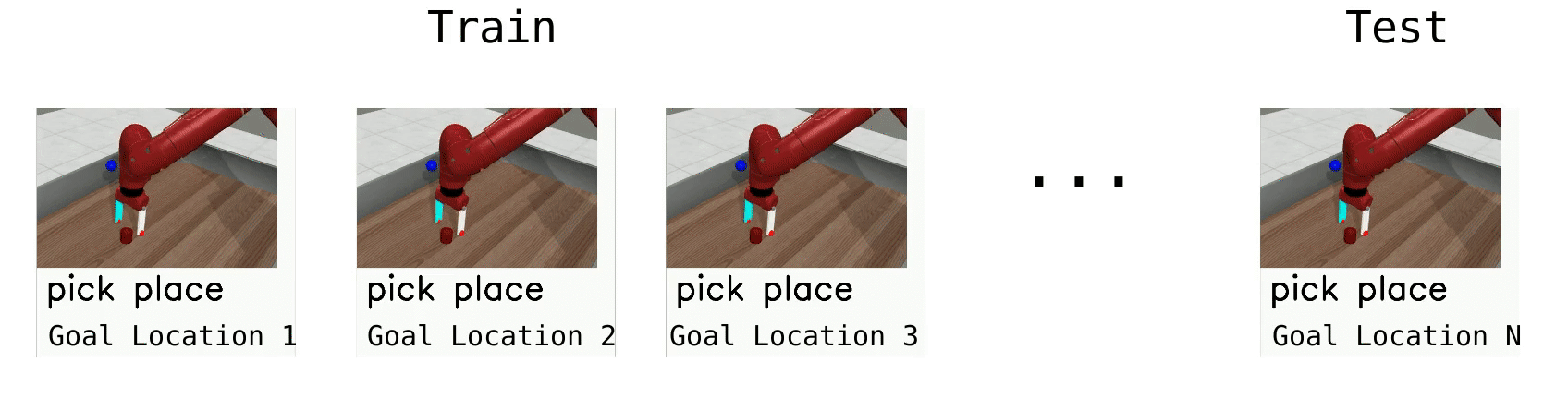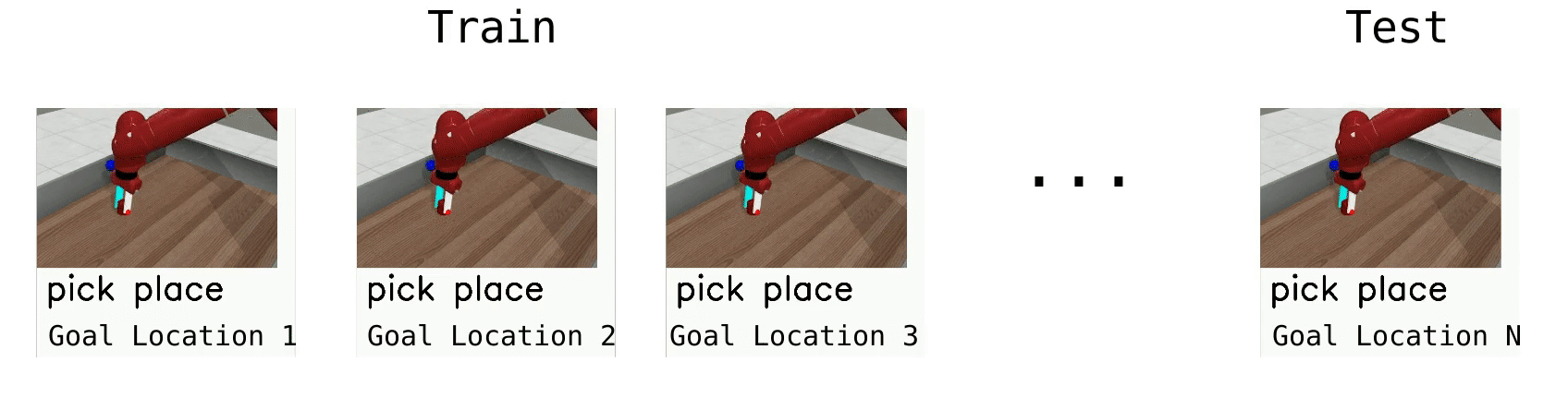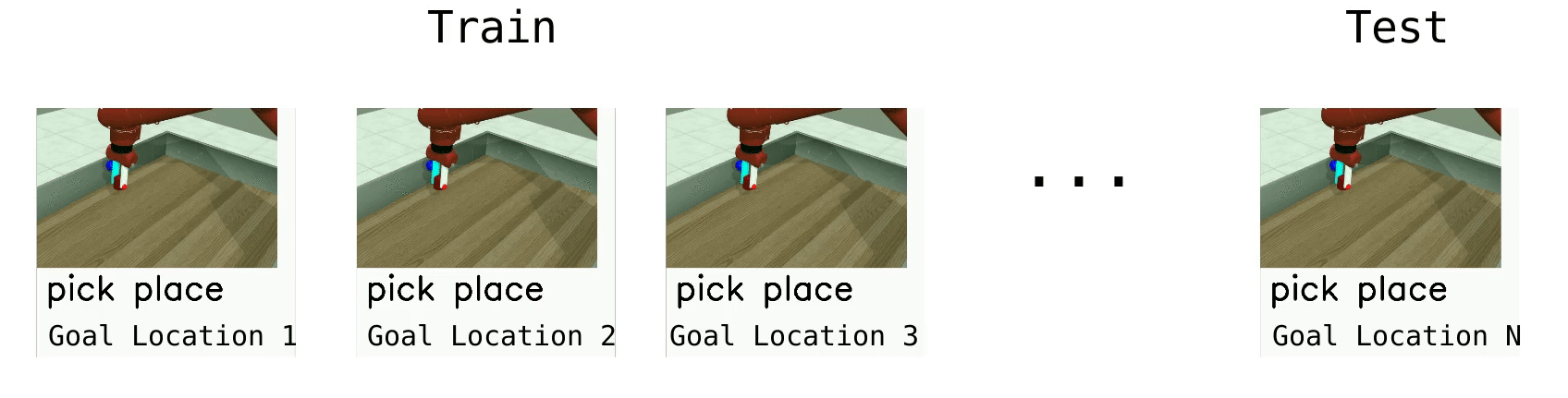
Meta-Learning 1 (ML1) is our easiest meta-learning evaluation mode. The setting is a single task manipulation tasks, where we try to reach, push, and pick and place an object to variable goals. At test time, we present goals not seen during training.
Multi-Task 1 (MT1)
Multi-Task 1 (MT1) is our easiest evaluation mode. The setting is a single task manipulation tasks, where we try to reach, push, and pick and place an object to variable goals, without testing generalization.
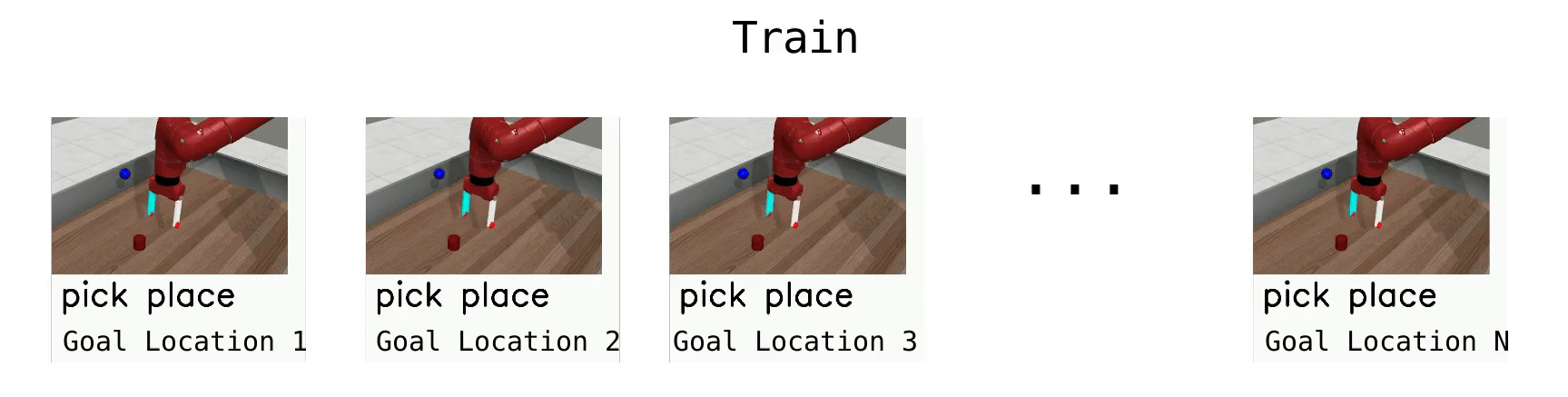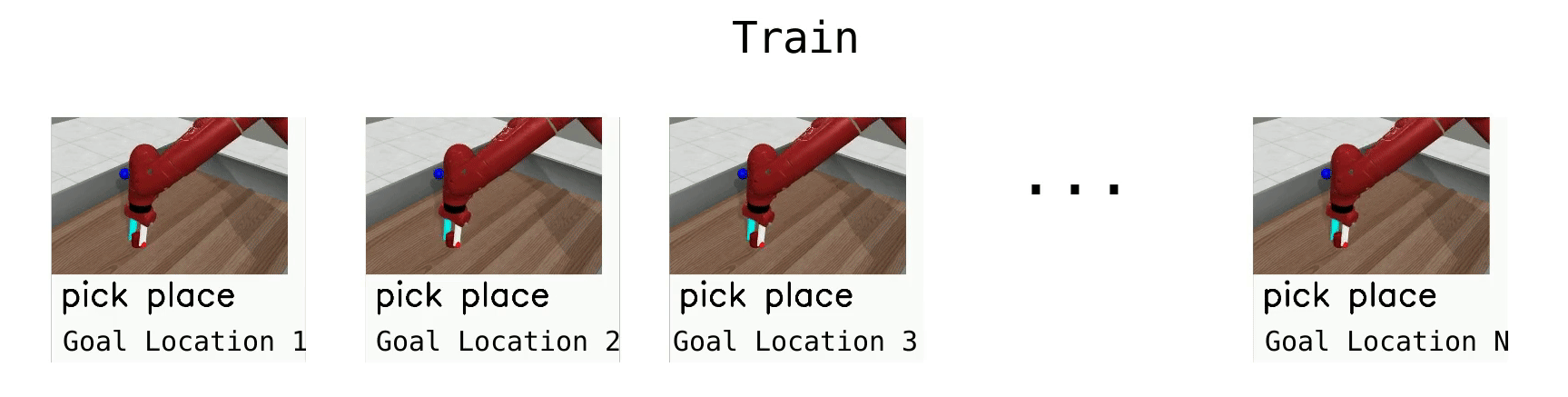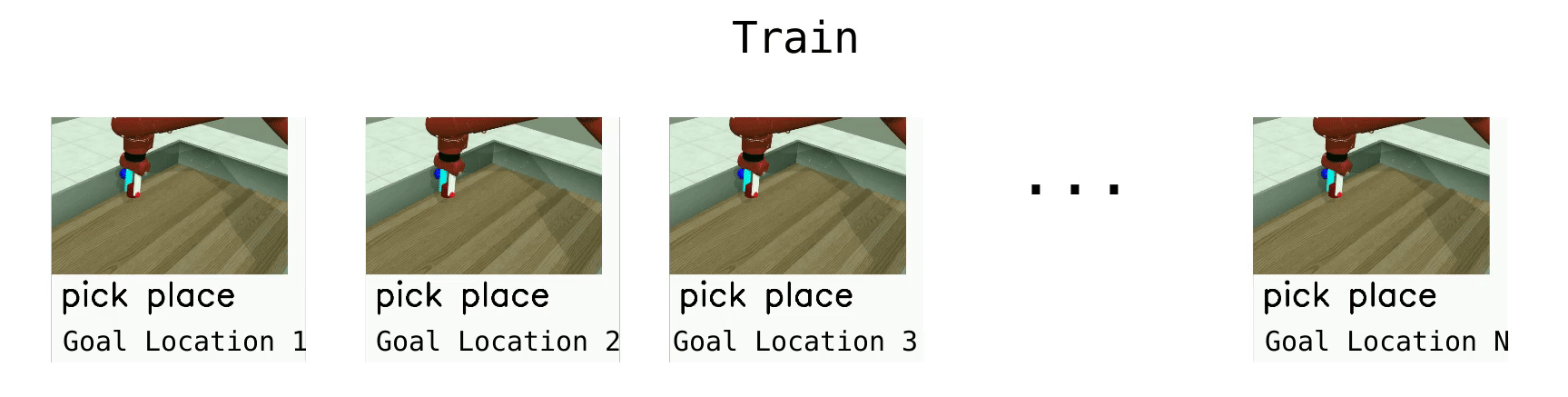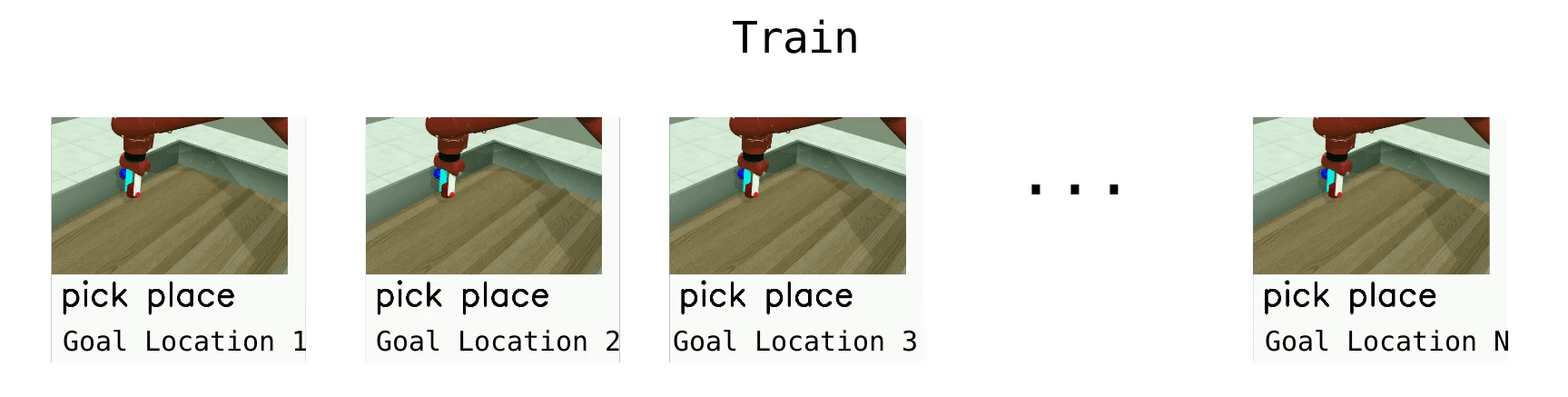
Meta-Learning 10 (ML10)
ML10 is a harder meta-learning task, where we train on 10 manipulation tasks, and are given 5 new ones at test time.
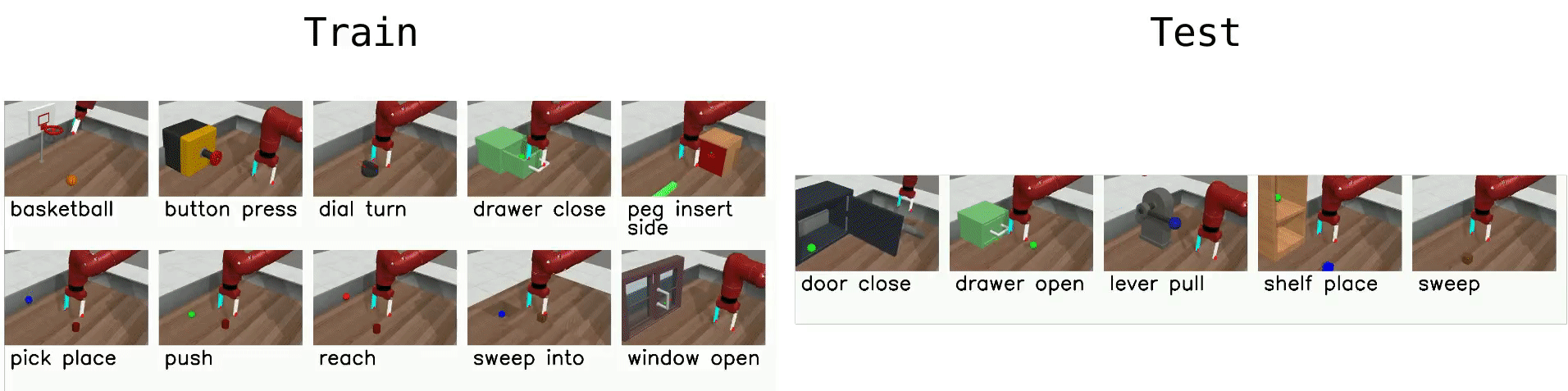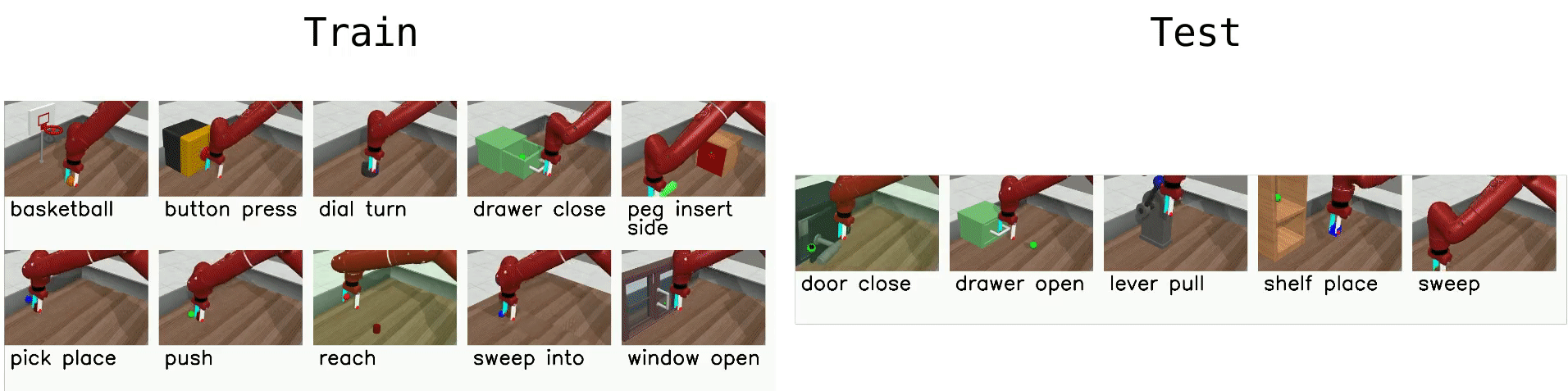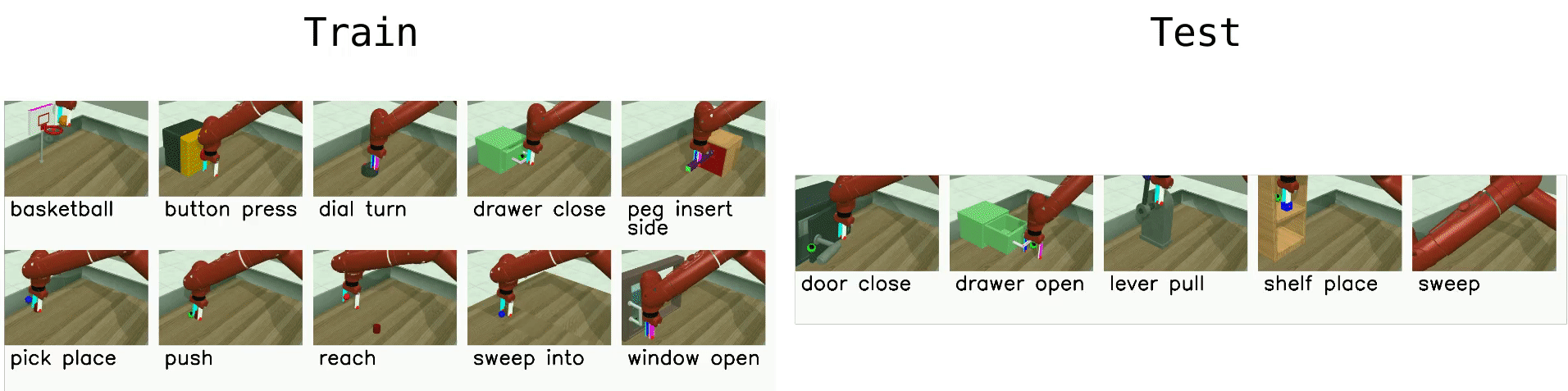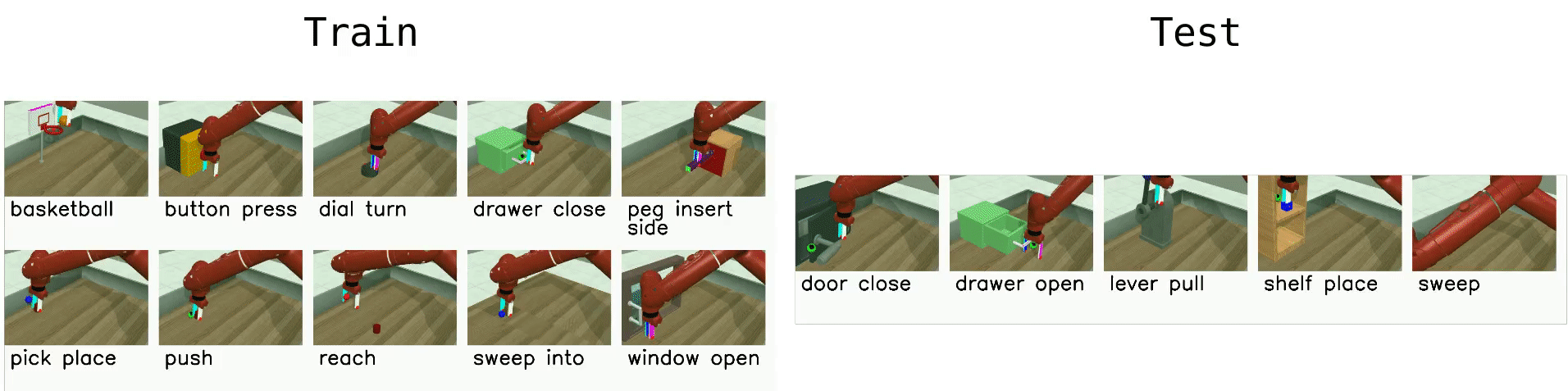
Multi-Task 10 (MT10)
MT10 tests multi-task learning- that is, simply learning a policy that can succeed on a diverse set of tasks, without testing generalization.
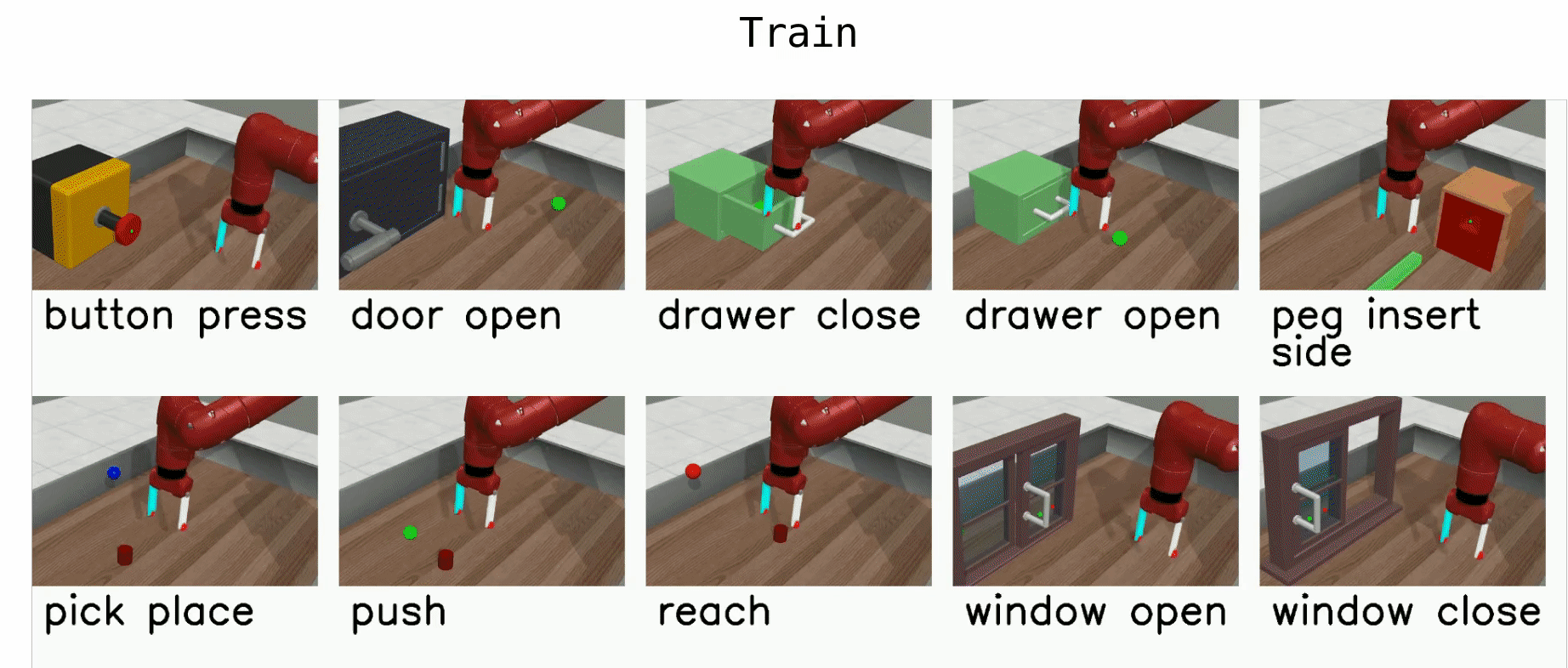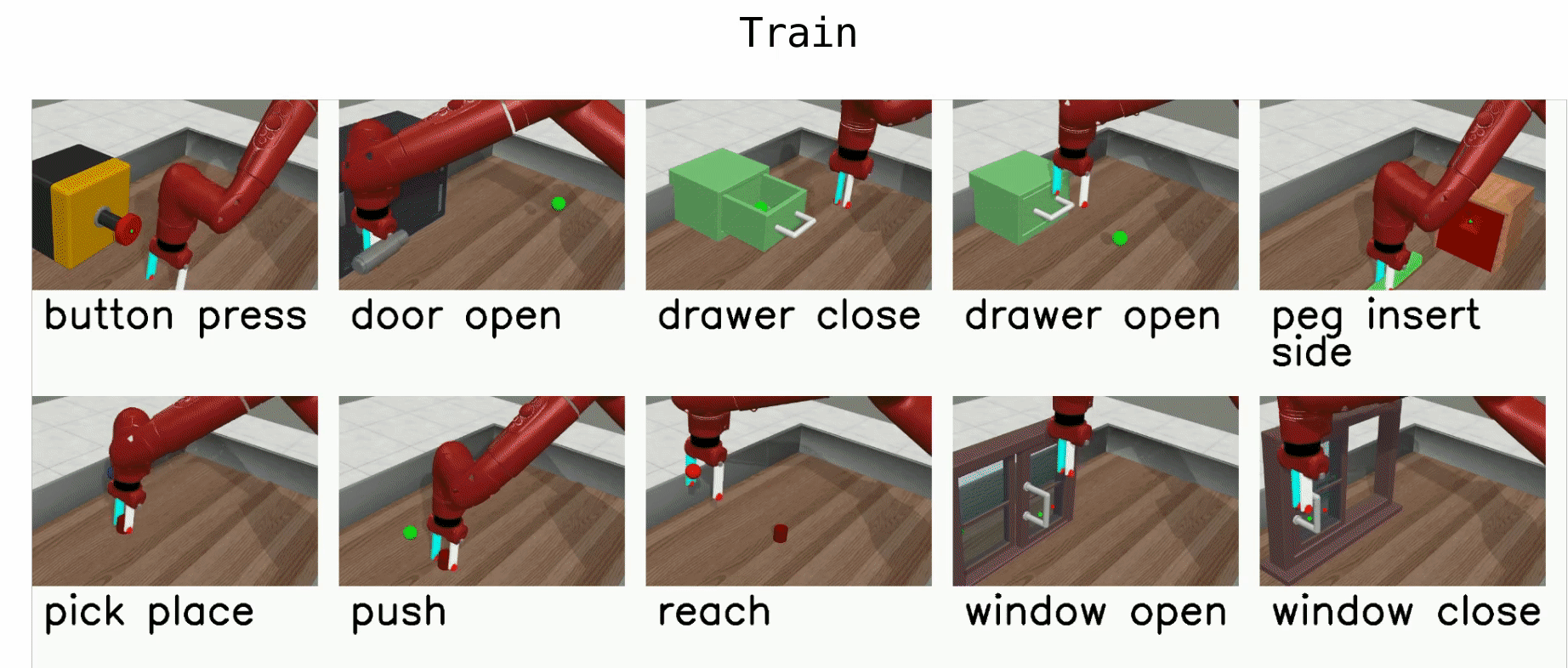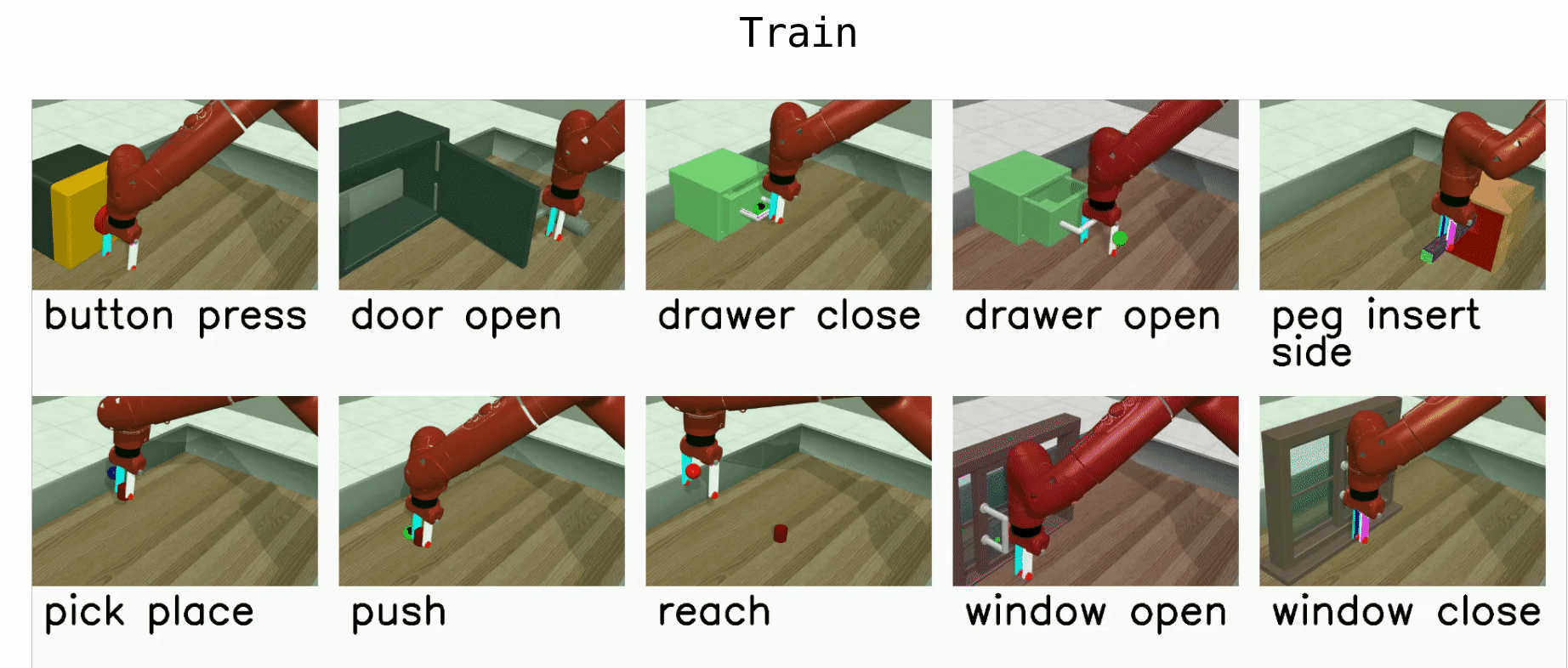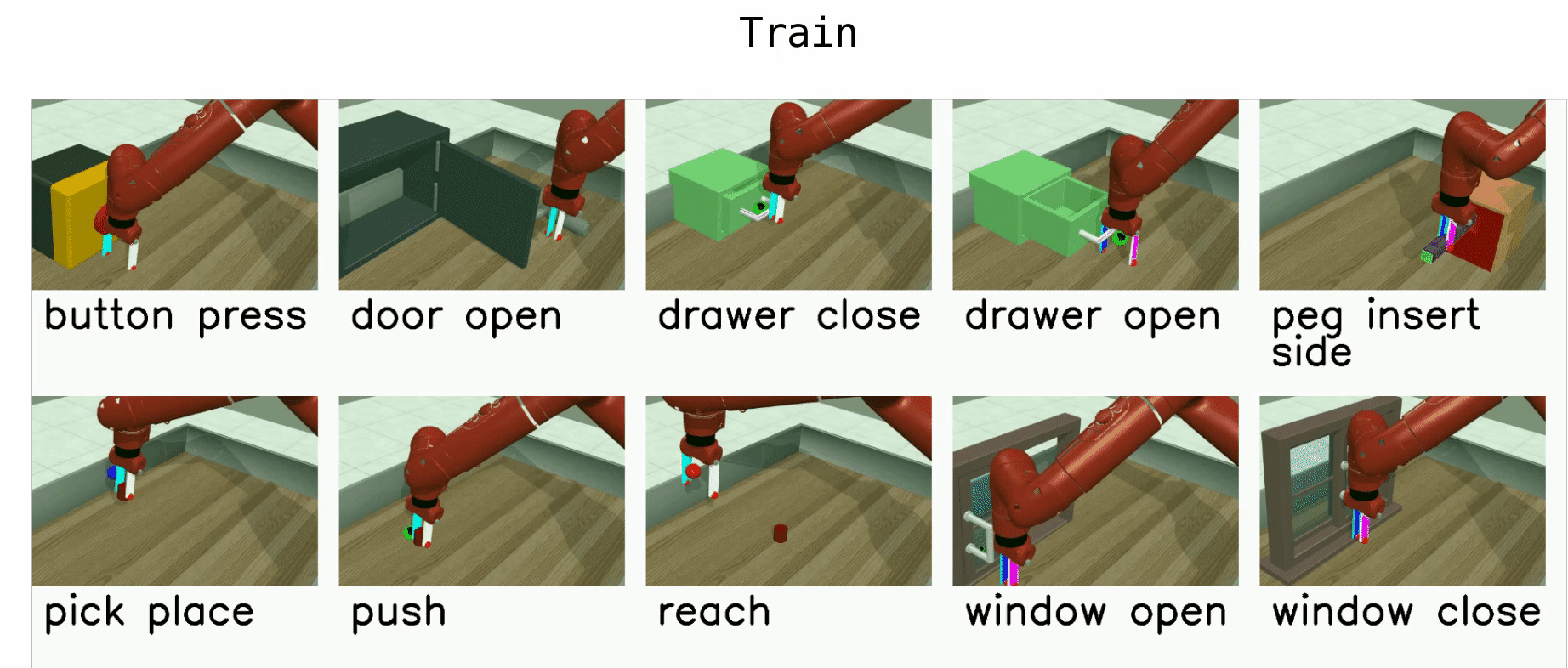
Meta-Learning 45 (ML45)
ML45 is a meta-learning mode with 45 train environments and 5 test environments.

Multi-Task 50 (MT50)
Finally, MT50 evaluates the ability to efficiently learn all 50 of the above manipulation environments.



 Ryan Julian
Ryan Julian


 Karol Hausman
Karol Hausman Chelsea Finn
Chelsea Finn Sergey Levine
Sergey Levine